APO的告警关联和告警故障影响面功能介绍

一般IT系统都会配置一系列告警来提醒运维或开发人员,系统存在问题。将告警进行分类之后,至少会有以下种类的告警:
- 系统运行资源告警(CPU、内存、磁盘)
- 网络质量告警
- Kubernetes事件告警
- 应用级别告警(延时、错误率、吞吐量)
- 中间件告警
可观测性系统比较棘手的问题是告警噪音,告警噪音在某些场景是真实有效的,而在某些场景下又成为了噪音。APO团队认为告警噪音很难避免,但是可以通过在业务接口维度进行区分,快速聚焦到对业务产生影响的告警之上。同时APO还提供了故障影响面功能,用以判断告警到底对用户直接操作的入口业务有没有影响,如果有影响,需要确定什么级别的人员该被叫进来作为主导者,以便更快地调动资源恢复业务。
传统告警的处理方式
运维人员根据其经验设置告警规则,每种告警其实都是有意义的,如果没有意义,完全可以不设置该告警。
但在实际场景中,经常会出现告警噪音,也就是这种本应该产生警示作用的告警,实际上并没有实现其效果,反而成为了噪音。
我们必须要承认一个事实:告警噪音是很难避免的。
告警噪音:通常指的是那些对实际系统健康或业务影响不大的告警
这类告警的出现原因有多种,主要包括以下几方面:
1. 阈值设置不合理(很难设置准确,因为相同阀值情况下,不同业务、相同业务不同压力都可能产生不同的后果)
传统的告警系统依赖于静态阈值,当某些指标(如CPU、内存等)超过预设的阈值时会触发告警。若阈值设定过于严格或不够灵活,就会导致许多不具备实际影响的波动也触发告警。例如,短时间的CPU使用率上升可能只是某个后台任务的正常行为,正常情况下并不会影响系统的稳定性,但如果阈值设置过低,系统仍然会产生告警。但是也有可能某些业务的延时波动就是该波动导致的。
2. 指标波动过大(绝大多数情况下,即便是无效告警,也是一种信息提示)
一些系统和应用在正常运行时,某些指标会有自然的波动。如果这些波动频繁触发告警,但并没有实际问题,这些告警会成为噪音。没有考虑系统的正常波动范围和基线,很容易导致无效告警,但是某些情况下,告警也确实会提醒故障,所以很多时候告警的阀值就会保持不动。
传统告警方式总结
传统告警非基于智能基线的告警有其存在的理由,阀值肯定是针对某些业务有效果的情况下才配置的,指标如果波动过大,也确实需要告警出来,只是作为告警应该分级处理。
如果告警系统没有设置优先级(例如将告警分为“高”、“中”、“低”优先级),那么所有告警都被平等处理,导致一些不重要的告警与关键告警混在一起,无法及时区分真正需要处理的问题。
APO的告警分类展示逻辑
APO的核心页面设计是基于服务端点也就是业务接口来展示的,通过分析业务接口来判断告警是否真的产生了故障影响有助于判断哪些告警是真的告警,而忽略那些告警噪音。
APO的告警排查使用思路:
- 重点识别哪些服务端点代表的接口有异常
- 在接口详情中找到有哪些告警
- 判断故障影响面,告警是否很严重?需要拉上哪些人立马排查
APO首页告知哪些接口产生了异常

APO首页列出了所有接口的同比影响,并智能排序,只有接口同比有异常的才会排在前面展示,如果接口同比没有异常很可能是排序在下一页中,用户可能都不需要关心。
告警与接口的影响关系
系统运行资源告警(CPU、内存、磁盘)
系统运行资源告警(CPU、内存、磁盘)在首页中会以基础设施状态告警呈现,只要接口同比有异常且基础设施状态亮红灯,就可以确认基础设施状态影响了该接口的正常执行。

如果在首页中所有的接口指标变化不大,说明该系统运行资源告警(CPU、内存、磁盘)暂时不需紧急介入,如果有时间可以关注为什么产生该告警。

网络运行质量告警
网络运行质量告警在首页中会以网络质量状态呈现,只要接口同比有异常且网络质量状态红灯,就可以确认网络质量状态影响了该接口的正常执行。

如果在首页中所有的接口指标变化不大,说明该网络告警影响面很小,暂时不需紧急介入,如果有时间可以关注为什么产生该告警。

Kubernetes事件告警
Kubernetes事件告警在首页中会以Kubernetes事件告警状态呈现,只要接口同比有异常且Kubernetes事件红灯,就可以确认K8S事件影响了该接口的正常执行。

如果在首页中所有的接口指标变化不大,说明该网络告警影响面很小,暂时不需紧急介入,如果有时间可以关注为什么产生该告警。

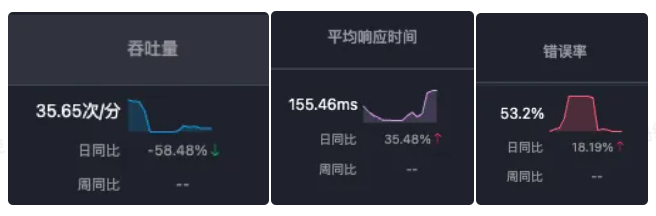
应用级别告警
应用级别的告警如果是延时、错误率、吞吐量的同比异常,那可以直接看查看接口详情,排查问题。
APO 的服务详情中的告警tab,列出来所有可能和业务接口有关的告警
例如:ts-travel-service出现了接口的延时同比上升或者错误率同比上升,可以在该服务中,查看所有该接口关联起来的告警信息,从而快速聚焦到这些告警之上。
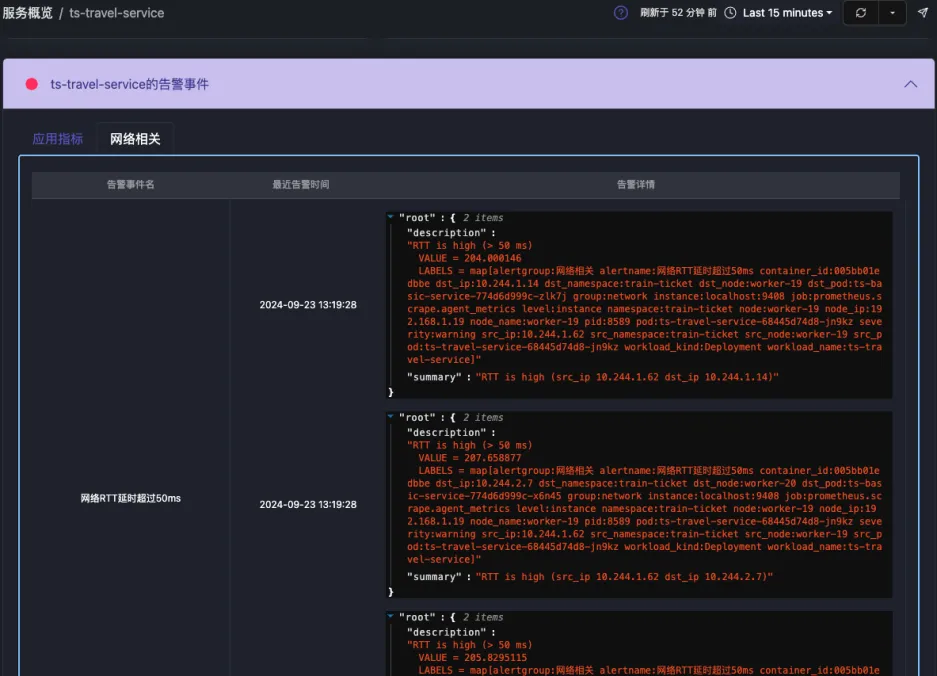
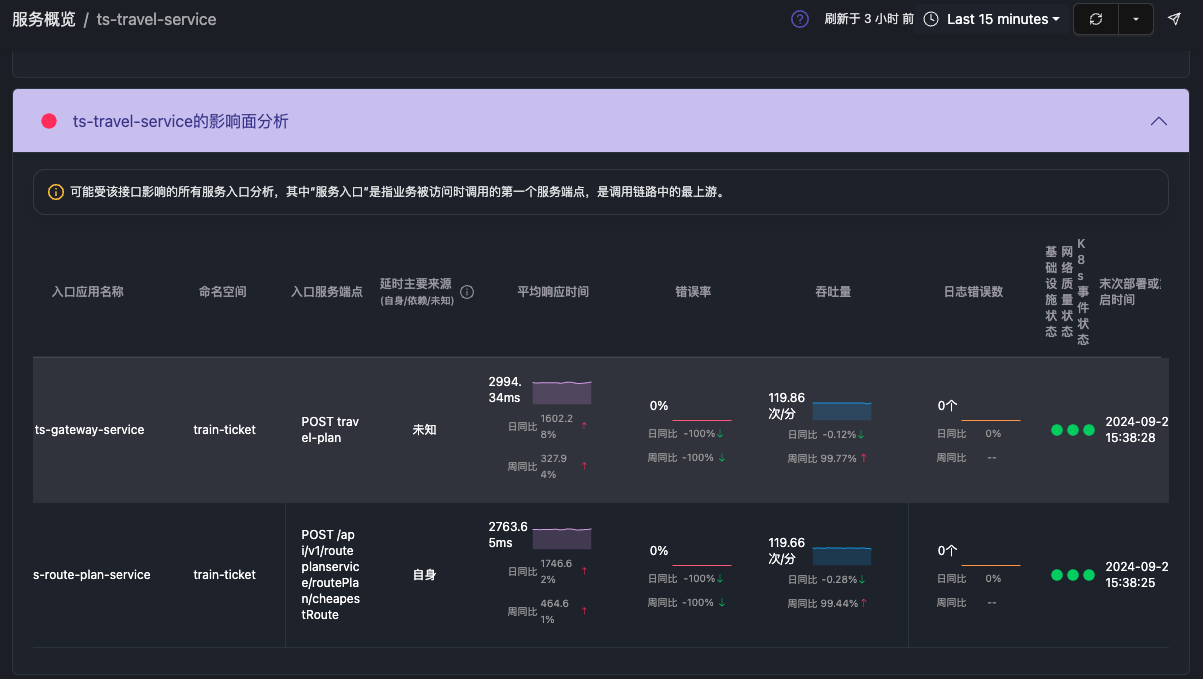
告警之后的第一步行为:告警的影响面分析
通过学习SRE相关知识或者告警处理的第一直觉,应该是判断这个告警的影响范围,也就是完成影响面分析,从而快速判断该告警是否会从简单告警演变成P0的故障。
告警的影响面分析不管如何做,最终需要回答以下的问题:
- 目前告警对哪些接口产生了影响?
- 这些接口又影响了用户使用哪些业务操作?
总结
告警噪音是很难消除的,而且告警噪音本身也是一种提示告知某些指标有异常。APO承认这个事实,推荐采用如下方式排查告警:
APO的告警排查使用思路:
- 重点识别哪些服务端点代表的接口有异常(如果没有接口有异常,说明告警都是告警噪音。当然要对告警分级,比如磁盘满,进程挂掉等场景都是严重告警和接口异常无关)
- 在接口详情中找到有哪些告警
- 判断故障影响面,告警是否很严重?需要拉上哪些人立马排查
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com