最佳实践解读:互联网公司线上故障标准化排障流程

线上故障通常是指影响线上服务可用性的问题或者事件,包括服务性能的降低、出现影响用户体验的问题、不同程度的服务不可用等。为了确保服务稳定性和用户体验,线上排障的第一目标是恢复线上服务或者降低影响。随着技术的发展,产生了诸如Google、Amazon、Twitter、淘宝、得物、字节等新兴互联网公司,其业务体量大,系统复杂程度高,时时刻刻服务成千上百万的用户,这都对故障处理的能力和及时性都提出了更高的要求。本文对互联网公司线上故障标准化排障流程做一简单分析,总结一些肤浅的方法论,以求共同探讨,共同提高。

故障处理目标
故障管理的目标是“尽快恢复服务到正常运行,并且最小化对业务运营的不利影响,从而尽可能地保证服务质量和可用性的水平”,即所谓的止血。即使不能立刻完全恢复,也要想办法将其影响降到最低,迅速止血。所��以往往重启服务、扩容、降级、熔断等方法都是在紧急情况下首先想到的方法,先试试再说,之后再彻查问题,从根本上解决问题。
实际工作中,找到了问题的根因原因,解决问题之后,并不代表本次处置就完成了。对于任何一个故障,其真正的处理目标应该是两方面,一方面尽快恢复服务,完成止血;另一方面要及时复盘总结,举一反三,不断完善流程处理机制,弥补操作过程中的规范问题,形成报告,在公司层面分享总结经验,提高应对能力的同时也要能够减少同类故障的发生。
故障处理思路
线上故障处理的目标是最快速度恢复线上服务或者降低对线上服务的影响,“快速”是对其最基本的要求之一,所以要要求故障发生时候需要能够最短时间发现,发现后要能最快对其进行评估和分类,同时根据评估结果能够充分调动各方资源最短时间内制定出可执行的应对方案,同时在整个处置过程中也都需要运维、业务研发、产品、基础设施等多团队互相协作,保持高效的沟通。基本的处理思路如下:
故障识别与告警
线上故障一般通过多种途径传递到开发、运维团队中,例如主动巡检发现,各纬度各类型监控告警,关联故障追溯,生产事件上报。首先需要对上报的信息判定是个例问题,还是确实是线上故障。以主动发现为根本建设目标,例如可观测性建设的目标和价值体现就�是能够将故障主动、及早发现和定位。
故障评估与分类
针对识别出的问题,进行严重性评估,判断问题的影响范围和严重性。根据评估结果,将问题进行分类,设定问题处理的优先级,同时通知各相关业务、技术部门人员故障情况,准备参与排查。进行评估分类需要多维度的数据支撑,往往缺失数据或存在盲区时更多依赖人员经验和能力。
故障定位与分析
确定故障后,需要快速定位到问题点,找到原因,以便针对性的采取合适的应对方案。在这过程中需要该故障涉及到的业务、开发、运维人员各负其责,分析系统日志,查找错误信息和异常行为,收集与问题相关的数据,如流量统计、错误率等,为问题解决提供依据。
该阶段是排障过程中最关键的阶段,往往无法估计具体时间,具体步骤往往也根据业务种类、问题表征、可观测性建设成熟度、团队能力等不同而有所差异,现阶段难以进一步标准化,所以也导致该阶段也是最难得一步。
这里举一个简单的例子,排查中往往是排查三板斧:模拟复现,找相关数据,分析完整请求链路。这其中找相关数据需要在各个可观测性工具里找到相关的数据,并将其关联,这是一个非常复杂且耗费时间的任务。同时,需要将这些数据,与其对应的 Trace 数据相对应,才能尽可能真实地还原出问题现场。但实际生产环境下,Trace数据茫茫多,人工分析几乎不可能,这也是为什么经常会重启服务、扩容、降级先试试看的原因。
故障排除与管理
根据问题定位和分析结果,制定相应的行动措施,执行对应的预案或采取合适的措施修复问题。同时在解决问题时,也需要遵循变更管理流程,确保每一步更改都有记录,以免派生出新的故障。
故障验证
在完成恢复或修复操作后,进行必要的测试,查看相应的监控指标数据,确保问题已经解决。同时恢复服务后,继续监控以确保系统稳定。将信息同步反馈到各干系人,如有需要,配合业务方完成故障期间受损的数据。
故障复盘
一般在故障处理结束后24小时内产出故障报告,包括故障过程回顾、故障原因分析、改进预防措施制定、故障定级等。故障定级分为P0、P1、P2和P3四个等级(依次降低),各公司都有特定的等级定义,主要从业务影响面和影响时间来确定。一些团队或公司会总结故障知识库,作为排障知识的传递方式,以期保证人员能力和经验能够进行复制。
排障流程的标准化

排障流程的标准化是指将故障处理的各个环节规范化、流程化,以确保在面对系统或服务故障时,团队能够快速、有效地采取行动。
通过对故障处理思路的总结,可以看到排障流程标准化存在的主要问题一方面是故障定位和分析难以快速完成,同时也无法标准化;另一方面人员能力和经验的差异也导致标准化处理的过程在很多团队难以落地。
相关案例
下面以一些互联网公司的故障处理流程为例以供参考,图片和资料均来自于网络。
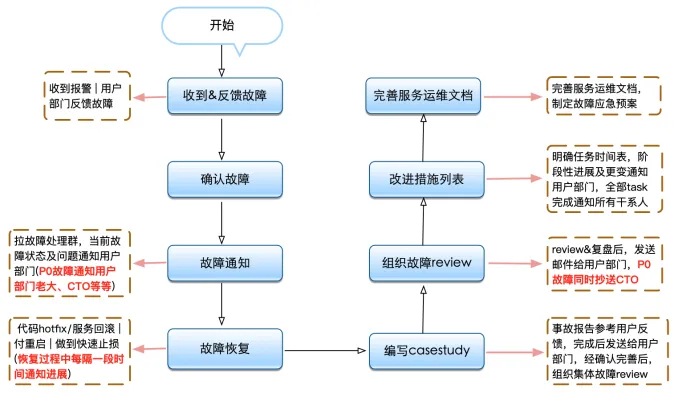
得物容器SRE响应流程
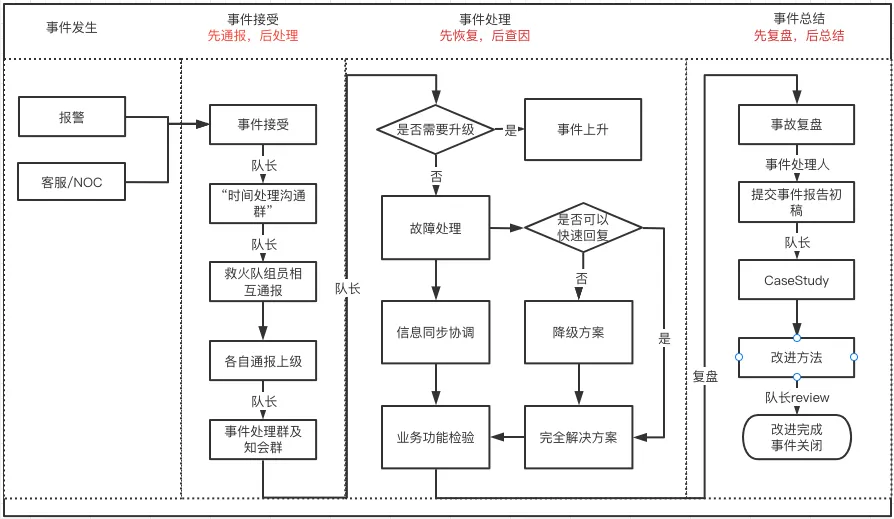
有赞故障处理流程
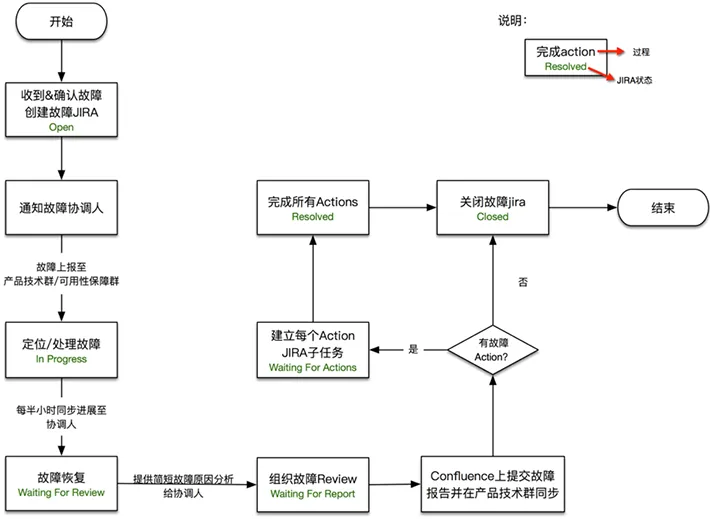
美团大数据运维故障处理流程
标准化排障流程需要体系和工具支撑
从上面的案例可以看到,标准化排障流程需要一套完整的体系支撑,以确保流程的顺利执行和持续优化。以下是构建支撑体系的几个关键要素:
1. 技术工具
-
成熟的可观测性体系:建立成熟完善的可观测性体系,能够确保尽早发现问题,同时排障过程中能够覆盖尽可能多的数据,以期最大限度消除观测盲区。
-
故障响应平台:能够对故障生命完整生命周期进行追踪,同时对各类指标数据进行治理,在故障时刻提炼相关联的数据,帮助处理人员聚焦核心指标。
-
知识库:建立和维护故障知识库,用于存储故障案例、解决方案和预防措施,为各类问题提供可执行的预案。
2. 流程文档
-
标准化手册:制定能够对于不同类型的故障能够统一执行的操作方法。
-
操作指南:为常见故障类型提供操作指南,帮助不同经验和能力水平的团队成员快速定位问题和解决方案。
3. 组织结构
-
专业团队:建立专业的技术和运维团队,负责监控、响应和解决系统故障。
-
角色定义:明确团队成员的角色和职责,确保在故障发生时,每个人都清楚自己的任务。
小结

线上故障处理的目标是快速止血,标准化排障流程是实现其方式的关键因素之一。通过建立一套完整的体系支撑,并不断优化排障流程,以期能够更好地应对系统故障,提高服务质量和用户满意度。
标准化排障流程的成功实施需要一套完整的体系和工具支撑。这包括组织结构、流程文档、技术工具、沟通机制、团队培训、持续改进等多方面因素。一方面很多团队很难像这些大型互联网公司一样真正落地故障处置规范,建立完备的可观测性��体系,花费人力物力进行数据指标的治理。另一方面很多企业建立的完善的可观测性体系,但是仍旧无法通过现有工具弥补人员经验、能力、操作方式、使用习惯的差异。这都使得标准化排障流程难以真正落地实施,致使可观测性数据价值无法被有效发掘。这些问题都需要平台化的能力和更先进的工具来解决。
随着技术的发展,特别是可观测性领域的发展,目前也出现了一些新工具能够帮助我们缩小这其中的差距,例如Datadog、Kindling-OriginX、X-Ray、Dynatrace等都通过各自不同的方法和理念去实现故障标准化排障流程。