故障注入是检验可观测性建设成熟度的有效方法

随着云原生、微服务等技术给企业带来竞争力的同时,也使得系统更加的复杂。日趋复杂的系统让故障根因难以排查,导致处理故障的大部分时间都用在了对问题的定位上。能够明确知道系统发生了什么是进行问题定位的前提之一,所以如何对系统进行监控,如何获取到规模庞大的系统的运行状态,也都成为了新的挑战,这种挑战反过来也促进了可观测性领域的发展。
可观测性的目标
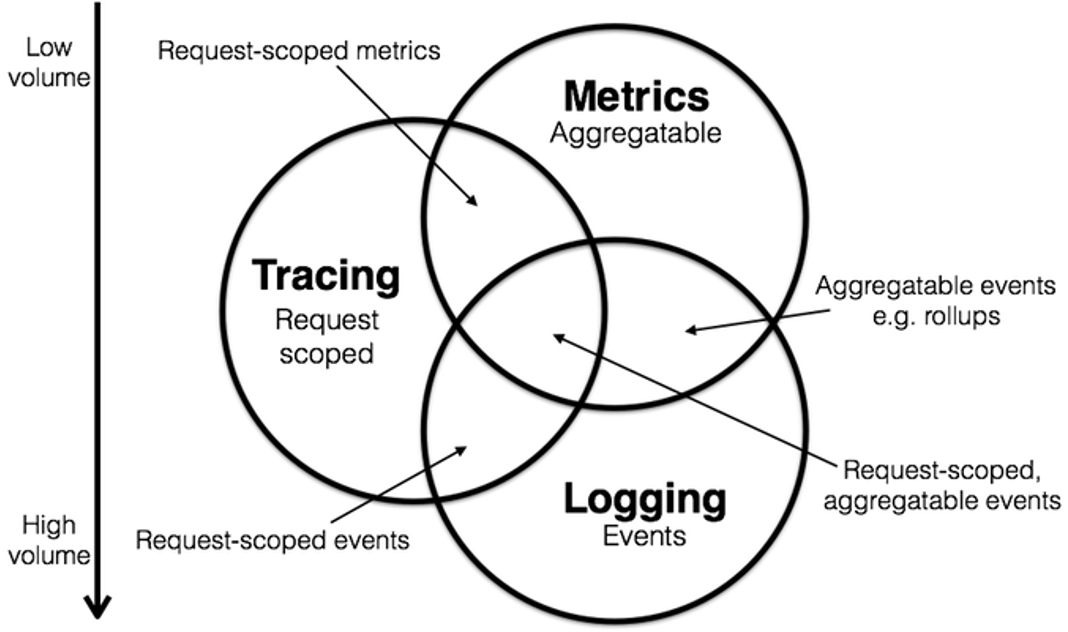
对于很多成熟企业,很多已经构建了APM、NPM等监控体系,以及Trace、Log分析系统等。而对于一些起步不久的企业,可能还处于可观测性建设的初期阶段。
那么对于不同阶段的企业和技术团队,是否对可观测性的要求有所差异呢?
总体上来说,可观测性代表了当前对系统形成洞察的能力,可观测性成熟度越高,对系统的洞察能力就越深入越完整,即系统的可观测性成熟度越高,就能越迅速、越准确地从发现的问题中找到根本原因。因此无论企业目前处于什么阶段,当前可观测能力的建设水平如何,其对于可观测性能力建设的目标应当都是一致的。
目标具体包括:
- 更全面的数据采集
- 更有效的关联各种类型数据
- 更快速与自动化的确认问题根因
各个企业在观测性建设成熟度上的差异,也主要体现在对这些目标的达成程度的差异。
可观测性成熟度
为了能够更好的帮助与指导企业进行可观测性的建设,衡量及评估自身当前可观测性建设水平,有很多机构与公司都发布过对可观测性成熟度模型的定义,本文以龙蜥社区与信通院稳定性保障实验室联合发布的《2023年可观测性成熟度模型白皮书》为例进行说明。该模型是一种用于衡量和评估企业软件系统内部可观测性的框架或方法,同时也是一种用于反馈企业可观测性体系建设成熟度水平的框架或方法。
该模型包含五个级别,分别是:
-
Level 1:监控。确定系统组件是否按预期正常工作。
-
Level 2:基础可观测性。确定系统为什么不工作。
-
Level 3:因果可观测性。找到问题的根本性原因,并确定它的影响面,避免再次发生。
-
Level 4:主动可观测性。自动化的找到问题根本性原因,自动化的响应处置,智能化的预测预防,阻止异常风险发展成为��问题故障。
-
Level 5:业务可观测性。确定对业务的影响,如何降低成本、增加业务营收、提升转化率、辅助商业决策。
可观测性建设成熟度越高,团队越能够通过合适的数据自动发现和修复问题,甚至主动识别和预防问题。可以简单理解为越多的故障能够通过可观测性工具发现,甚至主动预防,说明其成熟度越高,如果仍旧有较多问题通过客服侧或其他渠道上报而来发现,那么说明其成熟度还不够。
使用故障注入对可观测性成熟度进行检验
什么是故障注入
混沌工程是一种方法论,而混沌工程的核心就是注入故障。通俗理解,以应用为出发点,在各种环境和条件下,给应用系统注入各种可预测的故障,以此来验证应用在面对各种故障发生的时候,它的服务质量和稳定性等能力。
故障注入是衡量可观测性建设质量的有效标准
在实际生产�环境中,对可观测性建设成熟度及质量的最直接的衡量方式就是评估有多少故障是通过可观测性工具发现甚至预防的。
这是一个最直观的标准,如果花了很多精力、物力、人力做了完备的可观测体系建设,但是仍旧有大量的故障没有能够被观测到,甚至仍旧出现P0级别的故障,是没有人能够认同这个体系的建设是成熟的、是高质量的,只是单纯的可观测性数据和工具的堆砌。
而故障注入作为真实故障的模拟,与真实场景最为接近,也最能够有效地评估系统在面对实际故障时的响应和恢复能力,也最能够有效的反映出可观测性体系在实际问题场景中是否能够真实有效的发挥作用,为解决问题提供最切实有效的价值。业内技术领先的公司,也经常采用故障注入演练的方式对自身系统的健壮性进行检验,查漏补缺不断提高可观测性工具对问题发现和预防的比例。
故障注入虽不能涵盖全部的故障问题,但目前主流工具已能将大部分常见的网络、系统、代码、容器问题进行模拟,能够有效帮助组织评估、改进和发展其可观测性能力。Kindling-OriginX 在产品设计与开发过程中也使用这种方式进行能力的检验和产品的迭代。
总结
如果想要对自身可观测能力进行检验,也可与Kindling-OriginX Demo采用类似方式,在目标环境中部署soma-chaos。
soma-chaos 目前已支持的故障类型有:
-
网络类故障案例。例如丢包率较高、重传率较高、带宽限制打满、DNS故障、TCP建连延时高
-
存储类故障案例。例如IO延时高
-
CPU类故障案例。代码自身CPU使用率高、共享环境其�它进程抢占CPU
-
内存类故障案例。FULL GC频率很高、共享环境其他进程抢占Memory
-
代码类故障。代码抛出异常导致错误码返回、HTTP请求返回错误码
soma-chaos 是一个开源模拟故障案例集系统。该项目开源在龙蜥社区系统运维联盟之下,其中包括复旦大学SELab开源的业务模拟系统Train-Ticket、Chaos-Mesh开源云原生混沌工程平台、收集整理的真实故障案例集。欢迎任何单位和个人提交贡献故障案例,一起讨论故障注入实践或在使用过程中产生的任何想法和问题。