Trace实践的常见挑战:客户端数据与服务器端时延不一致

背景
在现代应用开发中,链路追踪技术(Trace)扮演着至关重要的角色。它不仅帮助开发者监控和调试应用程序,还对性能优化提供了极大的支持。然而,在实际操作中,客户端与服务器端的数据时延不一致问题经常出现,这对业务流程和技术实施造成了显著的影响。本文将探讨这一问题的具体表现、根源以及它带来的挑战,并讨论如何有效地解决这些问题。
Trace 技术概述
Trace 技术是一种监控和记录应用程序运行状态的方法,它可以帮助开发者了解程序在特定时间点的行为。通过 Trace,开发者可以获得请求路径、执行时间、关键代码函数执行细节等详细信息,这对于定位问题、监控系统性能以及进行后续的优化至关重要。Trace 技术在多种场景下都有应用,包括但不限于性能监控、故障诊断和系统调试。
Trace深入使�用的挑战:客户端与服务器端时间不一致的表现
只要深入使用过Trace的用户,一定会有这样的体验,Trace反映出客户端调用时间很长,但是Server端的执行很短。这会带来以下的问题
1. 归因错误
时间不一致会导致误导性的性能指标,使得开发和运维团队难以准确评估系统的真实性能表现。例如,如果客户端时间显著长于服务器端处理时间,可能错误地将问题归咎于服务器的处理能力,而实际上问题可能出在网络延迟或客户端处理上。
2. 浪费更多的人力成本
准确地定位问题源头变得更加困难。时间不一致可能掩盖了真正的性能瓶颈或错误所在,导致团队花费大量时间在错误的方向上进行调试和优化。
3. 数据准确性和信任度下降
长期的时间不一致问题可能会损害团队对 Trace 数据的信任度。如果分析和报告经常基于不准确的时间数据,团队可能会对使用这些数据做出的决策持怀疑态度,从而影响到决策制定的质量和速度。
造成数据不一致的原因
为了能让Cient调用时间和Server执行时间不一致原因更容易理解,我们先理解下Trace数据是如何来的:Trace数据来源是通过拦截某些函数而获得,Trace数据本质上反�映的是函数执行时间。
接下来让我们细化一次RPC函数调用的细节,从而分析可能造成故障的原因:
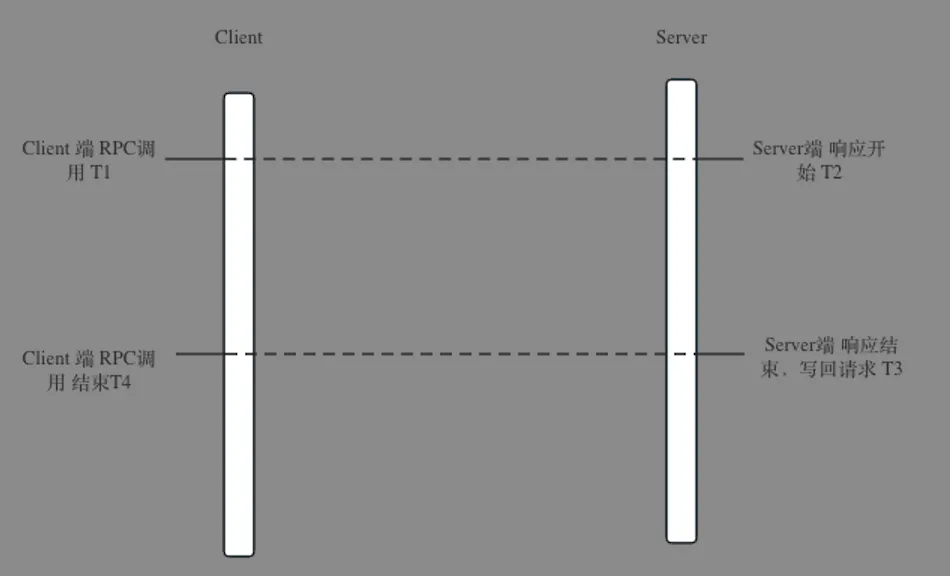
因为RPC的函数调用被封装成了本地函数调用,有些开发可能都不知道自己调用的函数其实是远程RPC调用,所以他们印象中的程序执行是这样的:client端执行RPC之后,Server端立马响应。
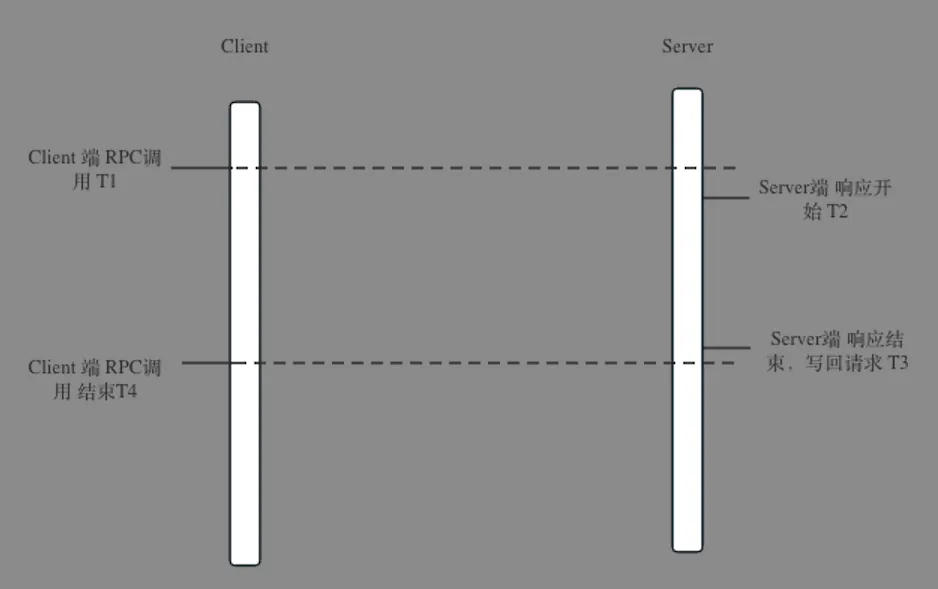
对网络有一定概念的开发,会认为rpc调用应该包含部分网络时间是如下图所示,server端开始时间比client端开始时间要晚,server端结束时间比client端结束要早。在这部分人的认知当中,一旦时延不一致,那就是网络的问题,但是网络很可能其实没有问题,请读者接着往下看。
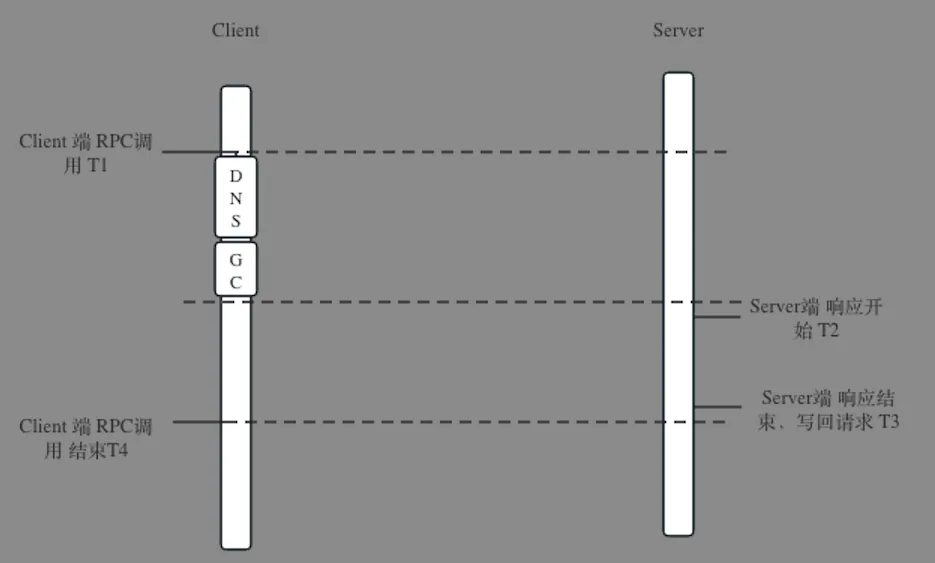
另外如果从client角度来看,调用就是rpc封装的函数,这个函数的实现绝大多数是没有问题的,但是也可能出现以下这种情况:client端出现GC,或者DNS寻址出现问题,也就是问题出现在了认知盲区,不知道client可能会出现问题。
Server端实际执行过程如下图:
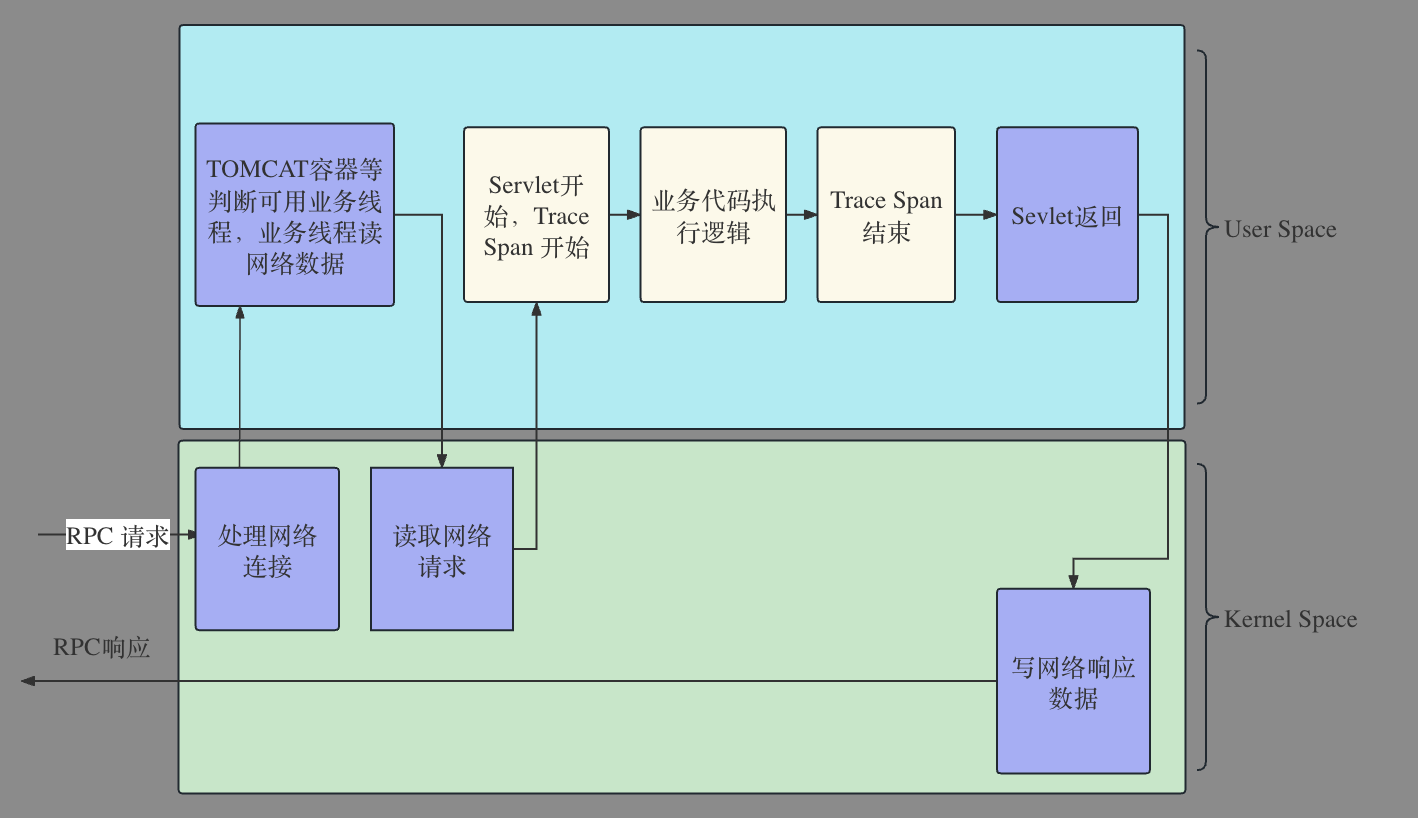
在一切正常的时候,图中紫色部分消耗的时间是�非常少的,基本可以忽略。但是一旦可能出现故障,每个紫色框都可能是个故障原因。
可能原因如下:
-
内核处理网络连接: 半连接,全连接队列满,导致连接建立很长,通常在大并发流量的场景下出现。
-
Tomcat容器耗尽可用业务线程: server端业务线程耗尽,通常在server端可能在雪崩中受到级联影响。
-
读网络请求: 如果网络质量出现问题,这段时间也会变长,还有网络带宽被打满的场景也会出现。
-
写网络请求: 如果网络质量出现问题,这段时间也会变长。还有网络带宽被打满也会出现。因为通常resposne是比较大的,这个时候如果client 与 server端的网络缓存配置不合理,出现网络full窗口或者0窗口也会出现问题。
-
任何在网络IO之前或者网络IO之后(Trace的拦截点位)可能的耗时操作。
挑战与问题
希望以上的说明帮助大家理解了client 和 server端执行时间不一致的可能根因。要能分析这个client与server端的时延不一致问题,要具备以下条件
-
深入理解程序执行过程的专家
-
深入理解网络执行原理
-
构建了非常丰富的可观测性数据
这些能力的积累可不是短期就能积累起来的,但是Kindling-OriginX 自带专家经验,自动对接Trace、DeepFlow、Prometheus等可观测性数据,在需要看什么指标数据之时,提供故障相关指标帮助用户深入理解故��障根因。