级联故障该咋办?

单个服务发生故障,有可能导致故障沿着调用链路,扩散至多个上游服务,进而可能会导致多个服务均产生不同的故障现象,这就是典型的级联故障。在级联故障中,常常会被复杂多变的故障现象所误导,进而选择了错误的排查方向导致不可能及时完成排障。面对棘手的级联故障,究竟该怎么办?
什么是级联故障
这里以一个例子来展示级联故障。在如下所示的服务调用结构中,对 ts-route-service 服务注入故障。之后受多种因素的影响,在 ts-route-service 的上游节点甚至旁路节点都出现不同的程度的故障现象,这就是典型的级联故障在实际系统中的现象。

为什么级联故障难以处置
这里继续以前文的系统为例,试试看能否找到故障。
该如何开始?
打开 Skywalking,筛选持续时间在 500ms - 10000ms 之间的近10分钟的请求数据,可以看到有667页近 10,000 条数据,这还是在并发量不大的情况下,如果稍有并发量这个数字更是难以想象,这么多 Trace 数据中究竟哪些有问题?哪些又能对我们定位帮助有帮助?该从哪些 Trace 数据着手开始分析?还没开始解决问题,就已经又得到了一堆的问题。
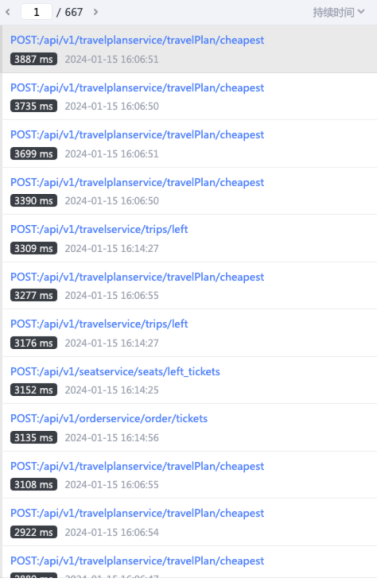
既然看似都有问题,那就先随机选择几条 Trace 数据,抓紧时间开始排障。
下面这条数据看上去是 ts-travel-service 有问题。
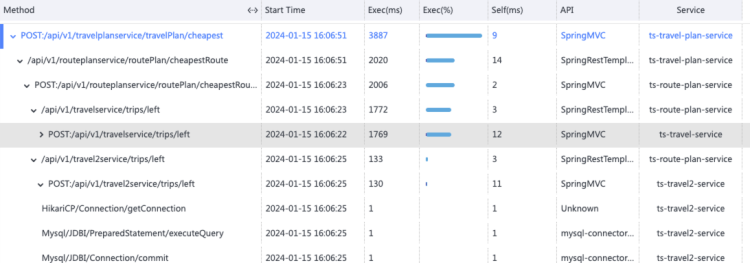
接下来这条看上去也是 ts-travel-service 出现了故障。
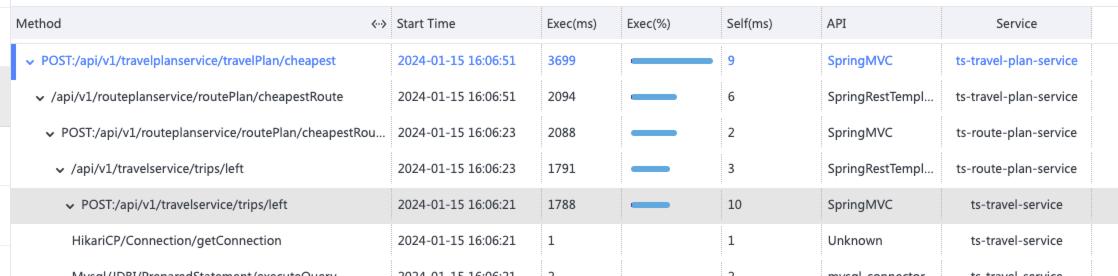
再打开一条显示 ts-travel-service 和 ts-basic-service 调用时间很长。
看到这里一头雾水就暂且认为故障发生在 ts-travel-service 或 ts-basic-service 。
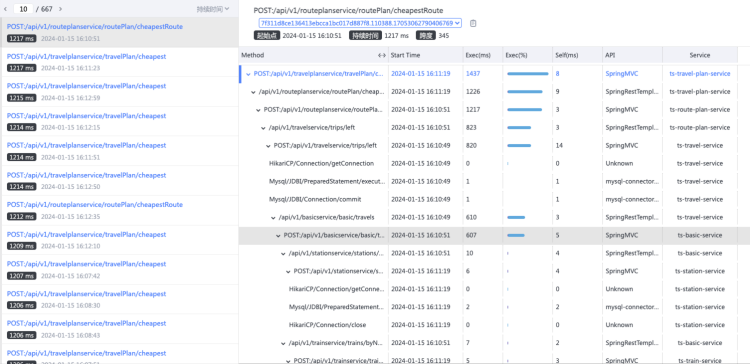
该如何选择,选择是否完备?
通过对 Trace 数据的分析,大致定位问题原因是 ts-travel-service 或 ts-basic-service 出现故障,导致链路在 ts-route-plan-service 调用下游服务时候出现问题。那么这两个服务该如何选择先处理哪个?系统中当前只有这两个服务出现了故障?是不是有可能两个服务都出现了故障?分析到这里我们得到的是更多的疑问。可事实上,在这里我们无论选择哪一个开始排查,都并不能找到造成问题的根因所在。实际情况中那只能重头来过,听天由命各凭本事了。
级联故障中一旦选错了排查方向就会导致做无用功,浪费了大量时间得到的是更多的疑问。传统工具的告警或 Trace 数据往往以单体应用的视角为出发点,更加容易分散注意力。大量的 Trace 数据反而会成为选择错误排查方向的诱因。在实际故障处置过程中往往变成无从下手,无法抉择。要不凭经验拍脑袋,要不就在所有人焦急的催促中不停地重启、穷举,希望能够撞个大运。

是否有更好的方法处理棘手的级联故障
面对棘手的级联故障,从本质来讲其实有两种优化手段
- 通过算法判断出故障线索之间的潜在依赖关系,从而找到故障的根因,这也是传统 AIOps 的思路。
- 重新组织故障线索,加快每个故障线索的分析,一分钟将�所有故障线索都分析出结论。
Kindling-OriginX 选择了第二种方式,通过 Trace 来组织故障线索,每个故障 Trace 都直接给出当前故障 Trace 根因报告。

重新组织故障线索
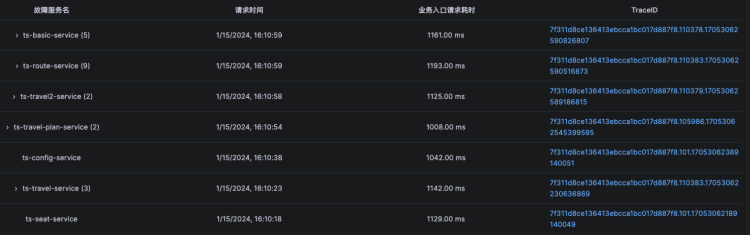
Kindling-OriginX 以全局视角切入,一方面将出现 SLO 违约服务入口的故障节点全部列出,以节点比例进行统计根因占比,另一方面聚合故障报告数据。能够在排障开始阶段就能够对全局状态有所掌控,不再盲目查找数据。
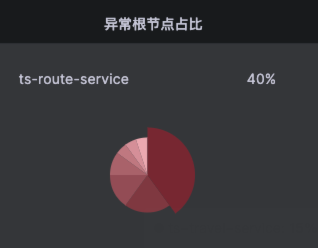
直接给出故障根因
Kindling-OriginX 在报告中已直接给出了故障根因,无需人工分析,即使像上图所示有多个节点的报告,也只需逐个打开查阅即可,而无需逐节点查找数据再进行人工分析。只需将全部故障节点报告逐个阅读后,统一判定即可,不用再苦于如何选择 Trace 数据进行排障。

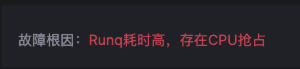
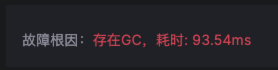
标准化级联故障排障方式
在复杂的级联故障中,通过 Kindling-OriginX 逐个查询全部故障报告后,结合排障优先级原则进行故障处置(被依赖的故障根因节点和基础设施故障「CPU、网络、存储」优先解决)即可。同时关联的各类 Trace、Log、Metrics 数据也为各职能团队进行定界与任务交接提供标准化的数据,这也能够使多团队协作排障有标准化的流程与依据。

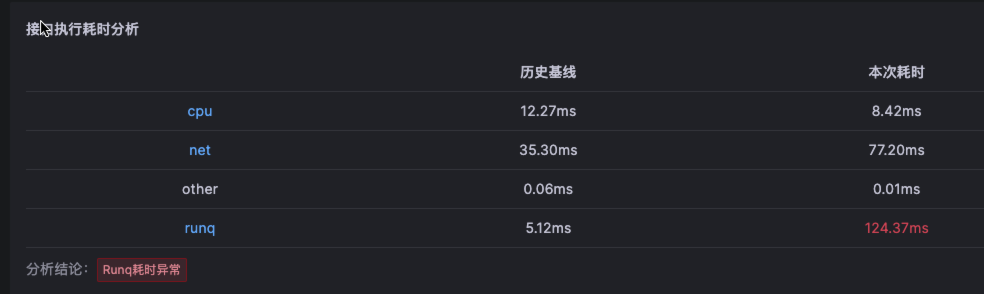

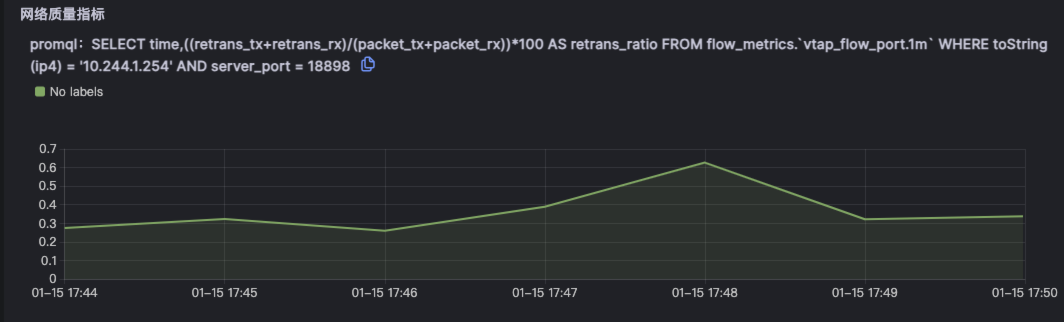 Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,�给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。
Kindling-OriginX 提供了一种新的处理级联故障的思路和方法,快速组织和分析故障线索,�给出根因报告,并根据优先级原则进行故障处理。这种方法可以加速故障定位,避免级联故障中排查方向错误,同时能够以标准化的流程进行级联故障的排查,真正的有机会去在实践中落地 1-5-10 故障响应机制。