内核视角下持续剖析 VS 代码视角下的持续剖析

火热的eBPF技术当下在可观测性领域的应用热点有两个主要的方向:
- 从内核中打开网络黑盒拿到相关的数据
- 利用eBPF技术实现Continues Profiling
在GitHub上,国内外的 eBPF 主流开源软件是打开网络黑盒提高可观测性,另外一部分就是Continues Profiling,其中Continues Profiling最有名的就是Pyroscope项目,并被Grafana收购。
什么是Continues Profiling?
以下内容来自于GPT4的回答:
持续剖析(Continuous Profiling)是一种软件性能优化技术,旨在实时收集程序运行时的性能数据,如CPU使用率、内存分配、线程锁等待时间等。这些数据通常通过在代码中嵌入剖析器(Profiler)来收集,剖析器能够监测和记录应用程序在执行过程中的各种性能指标。
持续剖析的目标是帮助开发者理解应用程序在生产环境中的实际运行性能,从而发现性能瓶颈和优化机会。与传统的剖析(通常在开发或测试阶段进行)不同,持续剖析强调在应用程序的整个生命周期内,尤其是在生产环境中不断进行性能监控和优化。
持续剖析的好处包括:
- 实时性能监控:通过持续收集性能数据,开发者可以实时监控应用性能,及时发现和解决问题。
- 发现隐蔽的性能问题:某些性能问题可能只在特定条件下或在生产环境中出现,持续剖析帮助发现这些难以在测试阶段发现的问题。
- 优化资源使用:分析性能数据可以帮助开发者优化代码,减少资源浪费,提升应用效率和响应速度。
- 提升用户体验:通过优化应用性能,可以直接提升最终用户的体验。
持续剖析通过集成到CI/CD流程、自动化工具和监控系统中,成为现代软件开发和运维的重要组成部分。它使得性能优化成为一个持续的过程,而不是一次性的任务,有助于构建更高效、更稳定的软件系统。
最原始的Continues Profiling概念主要停留在CPU代码上的采集,形成火焰图帮助大家理解代码在CPU上是如何运行的。但是这点对于分析清楚线上的性能问题是不够的,因为线上代码是复杂的,程序依赖的条件不仅仅有CPU,还有锁、网络IO、磁盘iO等各种事件, 所以可观测性巨头如Datadog在他们的Continues Profiling理解中已经增加了很多。
代码视角下的持续剖析
Datadog对Continues Profiling的理解,可观测性的终极大杀器
Datadog其官网对Continues Profiling的能力定义:
- Never miss production issues originating from your code by continuously profiling every line across all hosts and containers.
- Enable engineers of all levels to swiftly spot and resolve problems using Watchdog AI's insights and suggested fixes.
- Pinpoint methods and code lines that are inefficient under production load, despite having performed well in pre-production environments.
- Find the root cause of slow requests by correlating spans with profiling data.
- Gain thread-level visibility into your requests to investigate parallelization, deadlocks, inefficient garbage collection, locks, and more.
- Determine exactly what your slow methods are spending time on — CPU, locks, I/O, garbage collection, and more.
从能力角度来看,Datadog的Continues Profiling能力像银弹一样,成为了可观测性的终极方案,无论什么问题,CPU, locks, I/O, garbage collection等各种问题,Datadog的Continues profiling都能够给轻松给出答案。
开源项目对Continues Profiling的理解,像Datadog学习
以Pyroscope为例,最开始的Pyroscope提供了eBPF为内核的OnCPU数据采集和内存相关数据采集能力,主要的分析的能力是CPU、内存分配对象、内存分配空间、在用对象、在用空间、Goroutines等多种类型。
最近去Pyroscope的官方Demo上看,发现其演进思路也基本上往Datadog的方向靠近了,出现了对于lock的持续剖析功能。
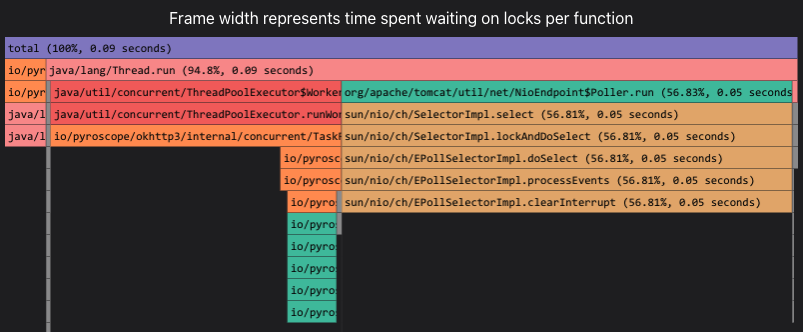
国内同行业专家也是非常认可Datadog的思路
某公有云可观测性软件发版了其持续剖析的功能,虽然没有实际使用过,从功能列表来看,已经很接近Datadog的能力了。
国内其他的可观测性公司也在致敬Datadog的方法论,提供类似的数据。
Datadog的Continues Profiling核心设计哲学
-
内核是稳定的
-
代码是业务开发的,开发者只关心代码要如何修改才能解决问题
-
火焰图长时间执行的代码块能帮助用户理解问题,并启发用户产生解决思路
-
正因为Datadog是沿着这个思路设计产品的,其持续剖析功能的实现就是从代码层面上去剖析问题,但是这样的设计哲学有一定局限性。
Datadog代码层面的持续剖析局限性
为了让大家更好的理解问题,举例说明,如果大家看到了这张火焰图能够得出什么结论:

从代码层面的持续剖析数据来看,代码是由于记录日志时间很长,那为什么呢?可能有常见的排查思路继续深入排查:
-
日志由于并行写,产生了锁
-
磁盘可能出现了问题,导致日志写变慢了
-
长时间的GC
如果上述的排查思路都没有结果,方向就比较迷茫了。
从内核视角的持续剖析
基于TSA的性能定位问题方法论
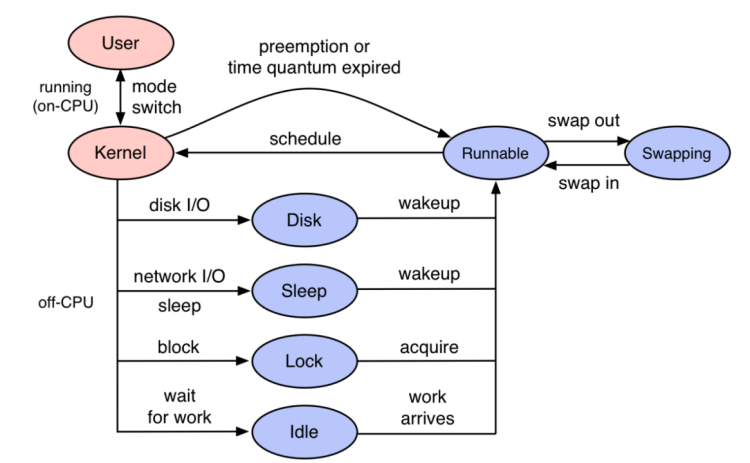
有兴趣的朋友可以深入理解大神brendan的文章The TSA Method,或者参阅TSA方法:基于线程时间分布分析性能瓶颈。
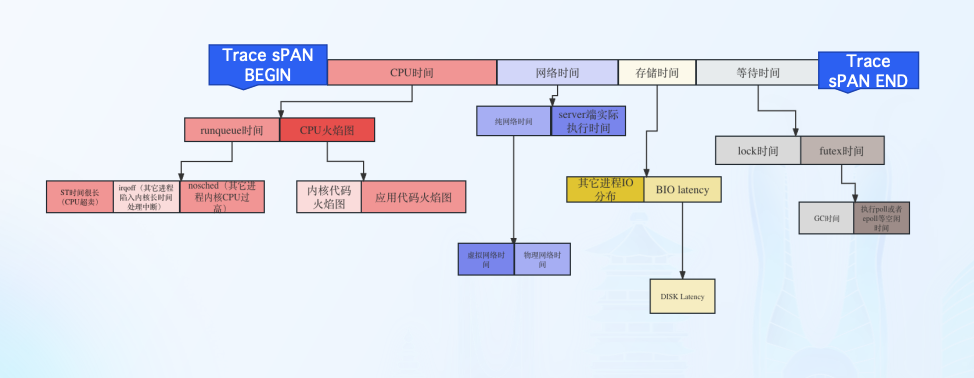
对于没有耐心的朋友,这里做个快速简介:就是将线程在不同状态下切换过程,按照下图所示对程序执行过程进行分析,从而理解线程在执行程序的时候到底卡在哪个环节。
从内核视角的持续剖析有什么优势和劣势
优势
-
真实反应程序正卡在什么地方
-
准确与精准没有任何其他可能性
-
内核反应出来的卡住的问题比代码卡住的问题场景少很多,线程只可能卡在以下几个方面:CPU执行,CPU调度,网络IO,磁盘IO,锁。这个为后续的智能化分析提供很好的基础
劣势
-
内核视角缺少业务属性,不知道哪个线程在哪个时间段为哪个业务服务,除非在性能压测场景,URL访问单一,可以在线程行为中找到模式匹配业务开始与结束,否则人很难分析
-
内核系统调用和相关知识对于普通业务开发人员而言太陌生,导致即便看到了内核相关系统调用比如说futex执行时间很长,不能理解这在代码层面上意味着什么
TSA的方法论结合Trace带来不一样的视角
开源项目Kindling的Trace-Profiling解决了单独TSA的持续剖析方法的劣势之一:内核视角缺少业务属性。Trace-Profiling通过TSA的方法论产生的数据与Trace打通,做到了与业务关联,这样在生产环境就可以做到某个业务因为什么原因卡住了。
还是以这个火焰图为例,代码剖析反应程序卡住在了日志代码之上。
 如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一
如果使用Trace-Profiling,应该能够明确给出当时业务是卡住下列事件之一
-
RunQ
-
Futex
-
CPU
-
DISKIO
代表代码执行的线程卡在什么地方知道了,那接下来就是如何理解和翻译了。
开发人员对内核的理解是推广TSA方法论的��阻碍
云原生环境内核由于资源竞争带来的问题
绝大多数开发人员在正常业务开发当中较少接触内核,而且也会认为内核是不会产生问题。也许从单机而言,出现任何问题都极少的可能是内核调度产生的。但是一旦涉及到云原生环境,要提高资源利用率的场景,就需要多业务都在竞争对内核的使用,这个时候产生的竞争就超出了普通开发人员的常规认识,也就意味着云原生产生的问题比以往问题更多。
开发者对于内核理解有限
CPU调度产生的RunQ对于绝大多数开发而言太遥远,上述例子可能事件中也就DISKIO是开发人员能够快速理解的,其它都需要花费更多的精力去学习。学习成本带来了推广难度,所以业界几乎没有看到基于TSA方法论的工业化产品在推广。
问题总结
-
基于代码的持��续剖析虽然对于开发而言足够友好,开发能看懂哪段代码带来的问题,但是由于代码的丰富多样性,看到代码卡住了,很多时候仍然不知道代码为什么卡住,并且现象可能有一定随机性。
-
基于TSA内核持续剖析的方法虽然能够精准定位业务卡在了什么内核事件之上,但是对于开发者不友好,不利于推广。
智能运维中的决策树结合TSA实现对内核事件的自动化翻译,完美解决当前持续剖析存在的问题
对于可观测性领域,AIOPS已经推广了很久,但是由于缺少一锤定音的数据特征,从而难以高准确率方式判定故障根因。
基于TSA的线程模型机制给出了程序的精准内核事件,相比于代码或者日志的N种场景,内核事件要精简得多。
举例说明:
一旦线程出现上内核事件RunQ,这说明线程在执行代码的时候,由于内核CPU调度的原因卡住了,这个时候在代码层面上可能在做一些做普通业务操作,比如前文例子觉得记录日志的代码卡住了,在代码层面上也可能是做了个网络操作卡住,从代码层面分析非常复杂,可能性非常多。但是从RunQ事件分析,就非常精准,只有这一个事件特征,不存在其他事件特征。
为了帮助用户理解,这��个RunQ的事件就可以翻译成为当前CPU资源不足,应该扩容了,这样开发和运维就能很容易理解。
基于内核事件统计分析,可以形成这样的决策树,最终就能完美定义出故障的根因。