磁盘故障!Demo环境全部宕机!
每一个微小的警告信号、每一个看似不起眼的小故障都可能是一场灾难的序曲。新年伊始Kindling-OriginX 内部Demo环境经历了一次由磁盘故障引发的重大事故,本文带大家一起回顾下这次看似由种种巧合因素导致的故障是如何发生的,又该如��何去规避。
故障回溯
-
这里简单介绍下整体环境情况,Kindling-OriginX 目前生产环境涉及到的全部集群和设施均在AWS中国区,分布在北京和宁夏两个AZ,依托此构建生产环境的容灾方案,后期会加入阿里云来建设多云容灾和就近接入。 而目前的演示环境相对就比较简单,集群在公司内的小机房内,各种容灾和电源方案都相对比较简陋,这也是这次故障的伏笔之一了。
-
开年的第一个工作日,我们发现内部的产品Demo演示环境的请求会不时出现无规律变慢。初始的直觉让我们以为是有用户在演示环境中体验故障注入,观察后发现在没有故障的注入的情况下,这种情况仍旧时有发生。此时我们打开 Kindling-OriginX 的慢请求根因分析报告,根据根因报告中的分析确定了问题的初因--磁盘I/O出现了异常,通过下方报告截图可以明确的看出主要耗时是由于文件I/O时长增大导致。之后查看机器相关数据后确定是磁盘坏道引起的。
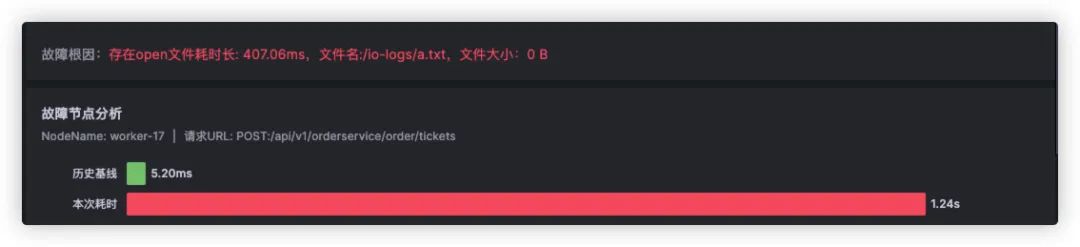
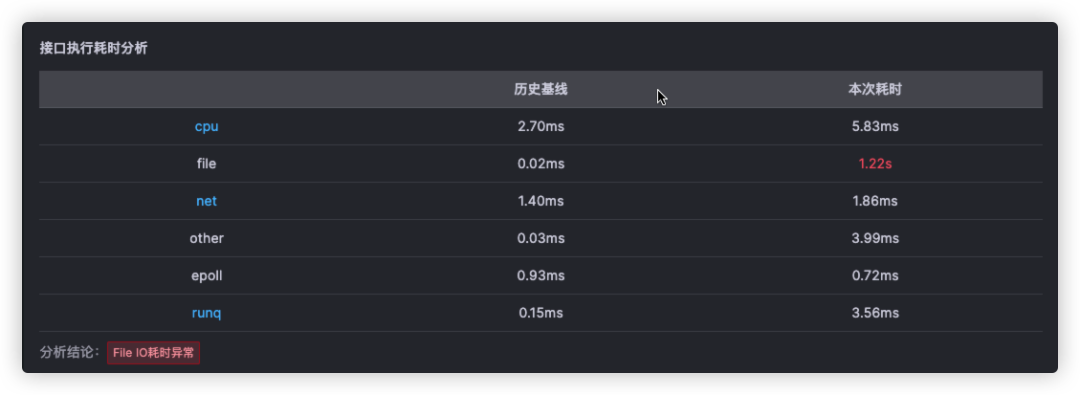
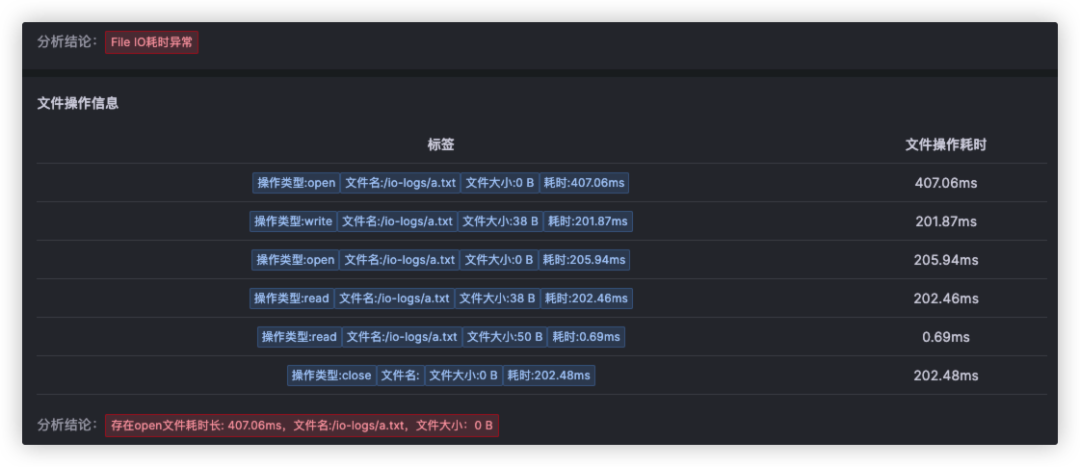
-
确定了慢请求是磁盘导致的后,这个问题并没有引起我们的重视,一方面磁盘存在一定的坏扇区或者坏道并不是致命故障,同时我们也乐观的认为这个情况也能更方便用户在使用Demo时体验磁盘故障。 接下来�又一个不幸再次发生,一天后该磁盘硬盘灯亮起了红灯,彻底宣告故障。但此时大家仍比较乐观,因为我们对Demo环境所在集群的 RAID5 还是颇为自信的,认为目前即使已经整盘挂掉,损坏一块短时间内也问题不大。然而,这种过于乐观的心态使得我们未能及时采取行动。我们的拖延,最终为后来的麻烦埋下了又一个伏笔。

-
明确问题后,开始了从供应商购买硬盘,并计划换盘时间的相关准备工作。和供应商沟通,快递收发货,安排合适的停机更换时间,由于之前的大意,每一个步骤都几乎耗费了2天的时间,甚至于拖拖沓沓。回头看来,整个过程都显得迟缓而被动。同时在这个过程中,这块问题磁盘彻底坏掉无法使用。
-
就在我们准备换盘的过程中,运气似乎并不站在我们这边,又一块磁盘宣告故障,RAID 状态也变为 FAILED,经过近一天的反复折腾和各种尝试后确定无法拯救。这次,RAID5的冗余也无法挽救数据的完整性,我们面临的是更加复杂的数据恢复和环境重建工作。
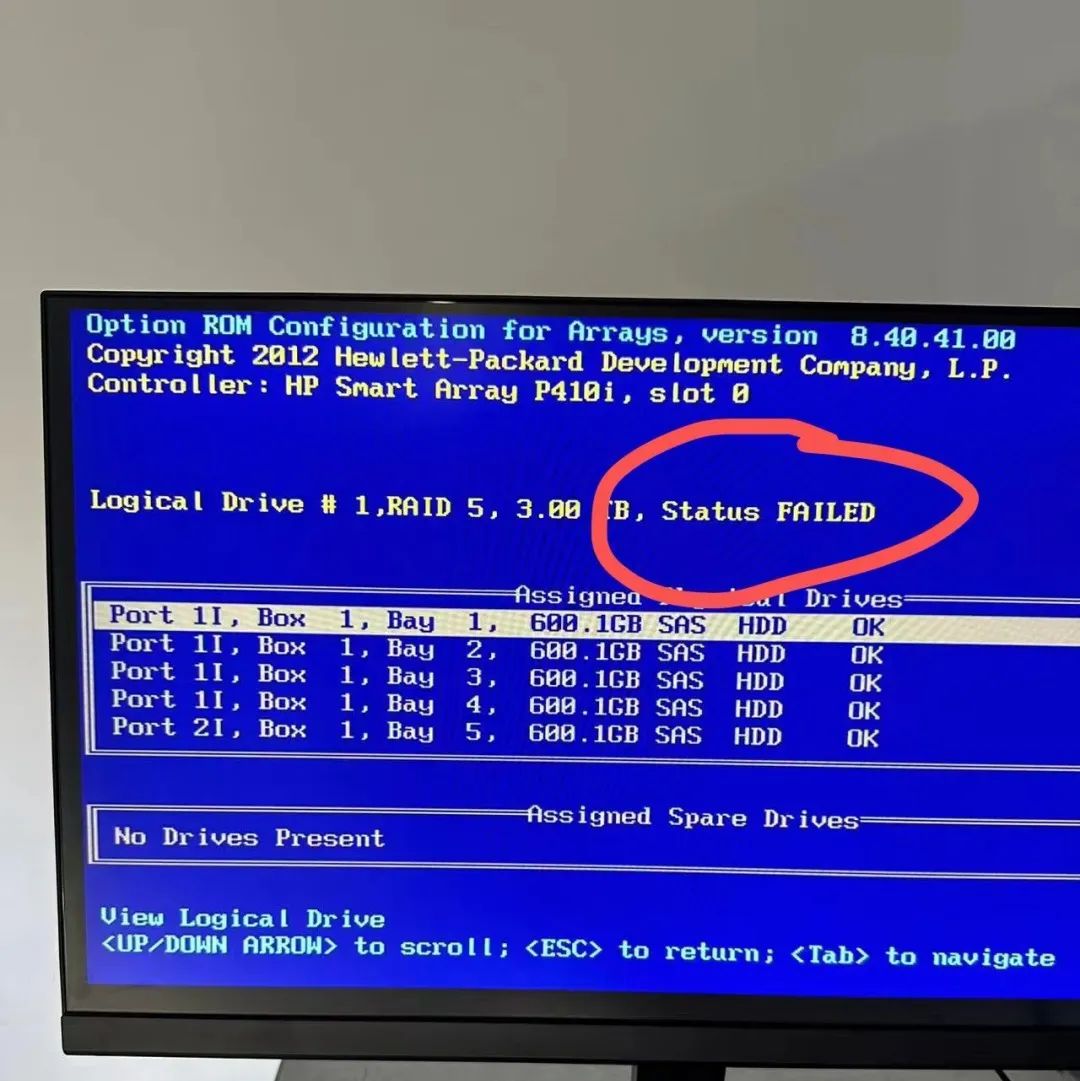

-
我们别无选择,只能从头开始,重建RAID5磁盘阵列,重新安装并配置整个环境。这一过程耗费了我们大量的时间和资源,演示环境也只能无奈的一直高挂免战牌。
-
经过漫长的重建、重装、环境分配、拉起各个服务各个环节后,1月6日周六晚一切终于恢复,整个故障从发现到完全恢复,耗时近��一周时间,算是开年第一周给自己好好的上了一课。原本一个小小的磁盘故障,也通过 Kindling-OriginX 的故障报告早早发现定位到,但却由于各种策略上的大意,认为是Demo环境在行动上没有足够的重视,让小故障变成了大事故,浪费了大量的时间和资源。
-
在经历了这次磁盘故障后,我们重新审视Demo环境故障的处置机制,以此为鉴,不只生产环境的稳定性和可用性需要得到保证,Demo环境同样需要有合理的机制和稳定性保证,不然同样会酿成大祸。
-
在事后复盘过程中,我们也对 Kindling-OriginX 在生产环境中高可用性、灾难恢复能力和扩展能力的设计方案进行了复盘和总结,确保在公有云自身的HA能力之上能提供更高的容灾恢复能力。在这里也推荐有条件的团队可以多尝试公有云,在容灾方案设计和高可用性方面很大程度上能够节约多人力和硬件成本,以AWS中国区通用性SSD卷为例,提供不超过十毫秒的延迟以及 99.8% 到 99.9% 的卷耐用性,年故障率(AFR)不高于 0.2%,这意味着在一年期间内,每 1000 个运行的卷最多发生两个卷故障。再配合合理的快照策略和可用区分配,几乎能满足大部分普通业务场景的可用性需求。还可以通过 AWS Fault Injection Service 在EBS上进行测试来进行故障演练和方案验证。
复盘总结
在问题出现的最早期,Kindling-OriginX 已经在第一时间给我们定位到了问题,并在根因报告中给出了问题故障根因,但是却没有引起足够的重视,最后在多种因素综合下变成了重大故障。也希望大家引以为鉴,故障的处置不仅仅需要第一时间发现、定位�、分析出故障根因,也需要在处置策略上有合理的流程,在战略上对任何有问题有足够的重视,才能真正的做到 1-5-10。
有兴趣的朋友们可以通过在线故障注入系统注入磁盘相关故障,体验真实系统中磁盘故障,同时通过 Kindling-OriginX 在线演示系统查看磁盘故障的根因报告。